Ongoing: Mining & Modeling Interpersonal Relationships in Unstructured Text
Summary | Synthèse
Most entity-relation extraction methods and objectives focus on syntactically simple relations that appear in the same sentence and do not require pronomial coreference, or anaphora resolution. We still do not have a good way to extract social relational information from unstructured text, and this is especially true for non-English texts. BookNLP, David Bamman’s project, provides an example of an intermediate step that is important: person name clustering with pronomial coreference resolution.
La plupart des méthodes et des objectifs d’extraction de relations entre entités se concentrent sur les relations syntaxiquement simples qui apparaissent dans la même phrase et ne nécessitent pas de coréférence pronominale ou de résolution d’anaphore. Nous ne disposons toujours pas d’un bon moyen d’extraire des informations relationnelles sociales à partir de textes non structurés, et cela est particulièrement vrai pour les textes non anglais. BookNLP, le projet de David Bamman, fournit un exemple d’étape intermédiaire importante : le regroupement de noms de personnes avec résolution de la coréférence pronominale.
Methods | Méthodologie
- Objective: extraction of relations in the following form: [Person 1] is [relation] of [Person 2].
- Challenge: Identification and inclusion of unnamed entities. This remains an unsolved challenge in Computer and Data Science.
- Approach: Pipeline: Resolution of pronominal coreference => Clustering of entities and pronouns => Classification of relations => Structured extraction of relations => Analysis of the resulting network
- Objectif : extraction de relations sous la forme suivante : [Personne 1] est [relation] de [Personne 2].
- Défi : Identification et inclusion d’entités non nommées. Il s’agit d’un défi non résolu dans le domaine de l’informatique et de la science des données.
- Méthode : Créer le pipeline suivant : Résolution de la coréférence pronominale => Regroupement des entités et des pronoms => Classification des relations => Extraction structurée des relations => l’analyse du réseau résultant
Significance
- This problem remains an unsolved challenge in NLP, especially in non-English texts.
- By working on this task, we work toward equity across languages.
- Unnamed people in texts are often women and other marginalized peoples, so by including this feature in the task, we also work toward historical visibility and more equitable representation of marginalized people in history.
Importance
- Ce problème reste un défi non résolu dans le domaine du NLP, en particulier pour les textes non-anglais.
- En travaillant sur cette tâche, nous travaillons à l’équité entre les langues.
- Les personnes non nommées dans les textes sont souvent des femmes et d’autres personnes marginalisées. En incluant cette caractéristique dans la tâche, nous travaillons également à la visibilité historique et à une représentation plus équitable des personnes marginalisées dans l’histoire.
Foundational Analysis
“From the Margins to the Center: A Method to Mine and Model Complex Relational Data from French Language Historical Texts,” Presentation for the Alliance of Digital Humanities Organizations Annual Conference (9-12 July 2019, Utrecht, Netherlands).
Conference Abstract | Résumé de la conférence
In humanistic research, Named Entity Recognition is highly useful, but it mines surface data, rather than revealing the complex nature of relationships between these entities. Named Entity Recognition (NER) extracts the names of people, locations, organizations, and, depending on the model, may also extract references to money, percentages, dates, and times, in addition to a miscellaneous class. Although this is certainly useful, NER does not represent the richness of the documents with which we work. For example, consider this fragment from a nineteenth-century French chronicle of Ottoman Algerian history: “To further attach himself [to his ally], Pasha Hassan married his [ally’s] daughter, then he launched troops against the rebel…”[1] In just this short passage, which is not even a full sentence, we find several people referenced who are unnamed. If we look back at the text, we see that Pasha Hassan’s ally is Ben-El-Kadi of Kuku, Algeria, and the rebel is Abd-El-Aziz, but Ben-El-Kadi’s daughter is never named. This occurs frequently in historical source material. Those who remain unnamed are most often women, servants, slaves, and Indigenous people – the very people about whom scholars are most anxious to know more. This short paper presents a work-in-progress: a digital workflow and Python script to mine and model the relationships between extracted entities from French-language documents in order to grapple with the complexity of human relationships and cultures, as well as the perspectives of authors and their informants.
This short presentation will share the complete information extraction code, its accuracy, the resulting visualizations, and a brief analysis from the case study. The method presented has applications far beyond French language and the history of the Middle East and North Africa. For instance, with some adjustments for language, this method would be highly useful in the analysis of The Twenty-Four Histories of China, the official history of the Chinese dynasties between 3000 B.C.E. and the seventeenth century. More broadly, this approach will be of use to scholars interested in identifying and studying relational data, social positions, and networks of both known and previously unknown actors, particularly those who remain unnamed in the source material.
As a test corpus, this project uses four digitized, OCRed, and hand-cleaned nineteenth-century French chronicles of Ottoman Algerian history. The volumes range between 41,341 words and 170,737 words and cover the period 1567 to 1837 with a focus on Constantine, the easternmost province in Algeria. The challenge is to extract not only named entities and their relations to one another, but to extract unnamed persons and their relationships as well. In simple NER, the names Moustafa and Namoun, would be the only extracted data in the following sentence: “Moustafa avait épousé une des filles de Namoun,” but the daughter of Namoun who married Moustafa would not appear.[2] The goal of this project is to uncover the positions and roles of women in Algerian society, so it is essential to locate and retrieve data about unnamed people.
The built-in language models and extensibility of the spaCy natural language processing (NLP) library for Python makes it most suitable for this project.[3] Specifically, spaCy enables researchers to define entities and build custom information extraction systems. Additionally, spaCy’s library features a French language model that has a built-in tagger, parser, and NER, unlike the Natural Language Toolkit or Stanford’s CoreNLP Open Information Extraction system.
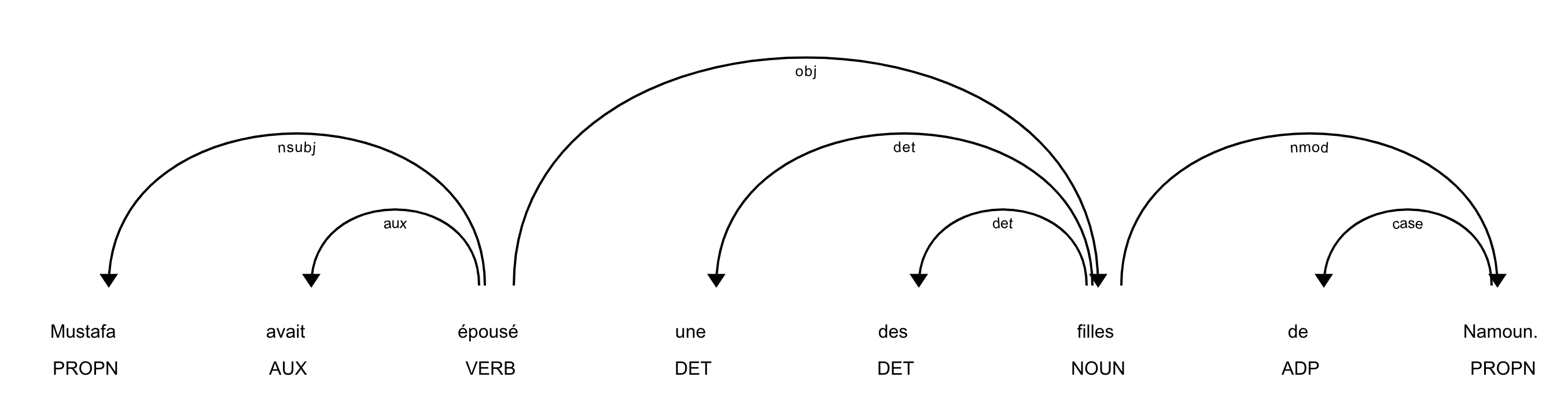
To build an information extraction system with spaCy that pulls the desired relational data, we must first identify an extractable pattern by parsing and tracing the dependencies of a sample sentence, as follows:
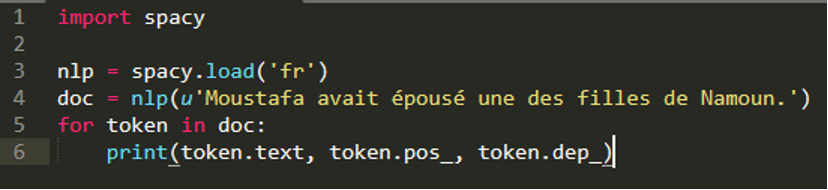
The code above results in the following output in the form: token, part-of-speech, dependency.
- Moustafa PROPN nsubj
- avait AUX aux
- épousé VERB ROOT
- une DET det
- des ADP case
- filles NOUN obj
- de ADP case
- Namoun PROPN nmod
- . PUNCT punct
SpaCy’s visualizer also allows us to view the dependency parse tree using the following code and sample sentence.
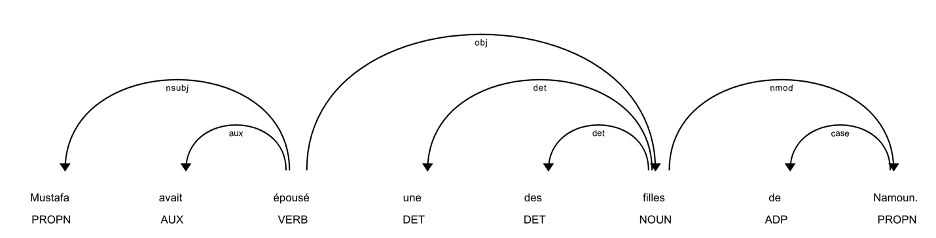
An examination of the parse tree above yields a pattern of parts-of-speech around the keyword “épousé” that we can use to extract the desired information about this relationship. Since we are interested in identifying the relationships between both named and unnamed people, we will look for specific patterns in parts of speech and syntax, as well as the location of proper nouns in relation to keywords. Based on an examination using the concordance method with the sample texts, the following keywords generated the best data: fils, fille, mariage, épous*, gendre, and beau pére (son, daughter, marriage, spouse/to marry, son-in-law, father-in-law). For example, the word “fils,” or “son,” yielded more consistent results for father-son pairs than the word “pére,” or “father.”
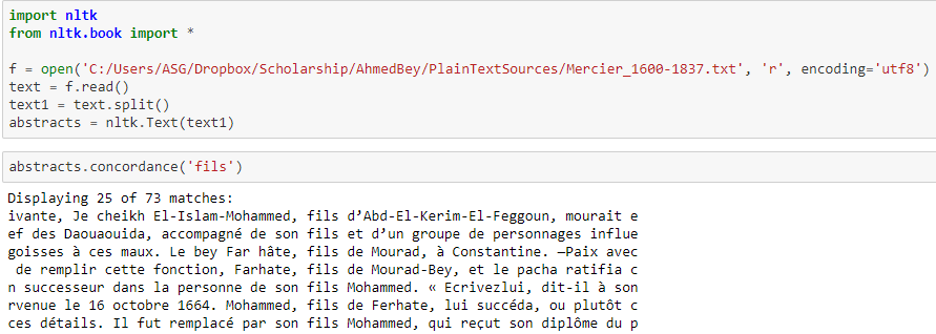
From an examination of the word “fils” in context, as shown above, general patterns emerged, which I then described in a plain text file for each keyword. The patterns for “fils” and the proper output format for each pattern are shown below. These outlines then inform the Python script that uses spaCy’s library to extract the relational data. This script will be made freely available on GitHub following the DH 2019 Conference.

Based on the examples and patterns above, the information extraction system derives relational data that easily translates into node and edge lists.
Network analysis of the extracted data, then, highlights how women, marriage, and kinship connections legitimated Ottoman rule in this case study. Initial findings suggest that women were essential intercultural mediators and conduits to power. Before the French invasion, Algerian women and their mixed ethnicity daughters were key links in the chain that bound Algeria to the Ottoman Empire.
Dans la recherche en sciences humaines, la reconnaissance des entités nommées est très utile, mais elle exploite les données de surface au lieu de révéler la nature complexe des relations entre ces entités. La reconnaissance d’entités nommées (NER) extrait les noms de personnes, de lieux, d’organisations et, selon le modèle, peut également extraire des références à l’argent, aux pourcentages, aux dates et aux heures, en plus d’une classe diverse. Bien que cela soit certainement utile, le NER ne représente pas la richesse des documents avec lesquels nous travaillons. Prenons par exemple ce fragment d’une chronique française du XIXe siècle sur l’histoire de l’Algérie ottomane : “Pour s’attacher davantage [à son allié], le pacha Hassan épousa la fille de celui-ci, puis il lança des troupes contre le rebelle…”[1] Dans ce court passage, qui n’est même pas une phrase complète, nous trouvons plusieurs personnes référencées qui ne sont pas nommées. Si nous reprenons le texte, nous constatons que l’allié du Pacha Hassan est Ben-El-Kadi de Kuku, en Algérie, et que le rebelle est Abd-El-Aziz, mais que la fille de Ben-El-Kadi n’est jamais nommée. Cette situation est fréquente dans les sources historiques. Les personnes qui ne sont pas nommées sont le plus souvent des femmes, des serviteurs, des esclaves et des indigènes – les personnes mêmes sur lesquelles les chercheurs sont le plus désireux d’en savoir plus. Ce court article présente un travail en cours : un flux de travail numérique et un script Python pour extraire et modéliser les relations entre les entités extraites de documents en langue française afin de saisir la complexité des relations humaines et des cultures, ainsi que les perspectives des auteurs et de leurs informateurs.
Cette courte présentation partagera le code complet d’extraction d’information, sa précision, les visualisations résultantes, et une brève analyse de l’étude de cas. La méthode présentée a des applications qui vont bien au-delà de la langue française et de l’histoire du Moyen-Orient et de l’Afrique du Nord. Par exemple, avec quelques ajustements linguistiques, cette méthode serait très utile pour l’analyse des Vingt-quatre Histoires de la Chine, l’histoire officielle des dynasties chinoises entre 3000 avant notre ère et le XVIIe siècle. Plus largement, cette approche sera utile aux chercheurs intéressés par l’identification et l’étude des données relationnelles, des positions sociales et des réseaux d’acteurs connus et inconnus, en particulier ceux qui ne sont pas nommés dans le matériel source.
Comme corpus de test, ce projet utilise quatre chroniques françaises du dix-neuvième siècle de l’histoire de l’Algérie ottomane, numérisées, océrisées et nettoyées à la main. Les volumes vont de 41 341 mots à 170 737 mots et couvrent la période de 1567 à 1837, avec un accent sur Constantine, la province la plus à l’est de l’Algérie. Le défi consiste à extraire non seulement les entités nommées et leurs relations mutuelles, mais aussi les personnes non nommées et leurs relations. Dans un simple NER, les noms Moustafa et Namoun seraient les seules données extraites dans la phrase suivante : “Moustafa avait épousé une des filles de Namoun”, mais la fille de Namoun qui a épousé Moustafa n’apparaîtrait pas[2] L’objectif de ce projet est de découvrir les positions et les rôles des femmes dans la société algérienne, il est donc essentiel de localiser et d’extraire des données sur les personnes non nommées.
Les modèles de langage intégrés et l’extensibilité de la bibliothèque de traitement du langage naturel (NLP) spaCy pour Python la rendent particulièrement adaptée à ce projet[3]. En particulier, spaCy permet aux chercheurs de définir des entités et de construire des systèmes d’extraction d’informations personnalisés. En outre, la bibliothèque spaCy propose un modèle de langue française qui intègre un tagger, un parser et un NER, contrairement à la Natural Language Toolkit ou au système CoreNLP Open Information Extraction de Stanford.
Pour construire un système d’extraction d’informations avec spaCy qui tire les données relationnelles souhaitées, nous devons d’abord identifier un modèle extractible en analysant et en traçant les dépendances d’un exemple de phrase, comme suit :
Le code ci-dessus produit la sortie suivante sous la forme : token, part-of-speech, dependency.
- Moustafa PROPN nsubj
- avait AUX aux
- épousé VERB ROOT
- une DET det
- des ADP case
- filles NOUN obj
- de ADP case
- Namoun PROPN nmod
- . PUNCT punct
Le visualisateur de SpaCy nous permet également de visualiser l’arbre d’analyse des dépendances à l’aide du code et de l’exemple de phrase suivants.
Un examen de l’arbre d’analyse ci-dessus produit un modèle de parties du discours autour du mot-clé “épousé” que nous pouvons utiliser pour extraire les informations souhaitées sur cette relation. Étant donné que nous souhaitons identifier les relations entre les personnes nommées et non nommées, nous rechercherons des modèles spécifiques dans les parties du discours et la syntaxe, ainsi que l’emplacement des noms propres par rapport aux mots-clés. Sur la base d’un examen par la méthode de concordance avec les textes de l’échantillon, les mots-clés suivants ont généré les meilleures données : fils, fille, mariage, épous*, gendre, et beau pére. Par exemple, le mot “fils” a donné des résultats plus cohérents pour les paires père-fils que le mot “pére”.
L’examen du mot “fils” dans son contexte, comme indiqué ci-dessus, a permis de dégager des tendances générales, que j’ai ensuite décrites dans un fichier texte pour chaque mot-clé. Les modèles pour “fils” et le format de sortie approprié pour chaque modèle sont présentés ci-dessous. Ces schémas servent ensuite de base au script Python qui utilise la bibliothèque de spaCy pour extraire les données relationnelles. Ce script sera mis à disposition gratuitement sur GitHub après la conférence DH 2019.
Sur la base des exemples et des modèles ci-dessus, le système d’extraction d’informations dérive des données relationnelles qui se traduisent facilement en listes de nœuds et d’arêtes.
L’analyse de réseau des données extraites met alors en évidence la manière dont les femmes, le mariage et les liens de parenté ont légitimé le pouvoir ottoman dans cette étude de cas. Les premiers résultats suggèrent que les femmes étaient des médiatrices interculturelles essentielles et des voies d’accès au pouvoir. Avant l’invasion française, les femmes algériennes et leurs filles d’ethnies mixtes étaient les principaux maillons de la chaîne qui reliait l’Algérie à l’Empire ottoman
[1] Ernest Mercier, Histoire de Constantine (Constantine, Algeria : J. Marle et F. Biron, 1903), 200. http://gallica.bnf.fr/ark:/12148/bpt6k5735219v.
[2] “Moustafa married one of Namoun’s daughters.” Eugene Vaysettes, Histoire des derniers beys de Constantine : depuis 1793 jusqu’à la chute de Hadj-Ahmed (Constantine : Grand-Alger-Livres, reprinted 2005), 52. (Author’s translation.)
[3] Matthew Honnibal and Ines Montani, spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and in