Bias Detection
Summary | Synthèse
Using a combination of hierarchical topic modeling with the Latent Dirichlet algorithm (LDA) and sentiment analysis with the VADER sentiment analysis package revealed hidden narratives about Jewish people, as well as other frequently marginalized voices in accounts of Algerian history.
L’utilisation d’une combinaison de la modélisation hiérarchique des sujets avec l’algorithme Latent Dirichlet (LDA) et de l’analyse des sentiments avec le logiciel d’analyse des sentiments VADER a révélé des récits cachés sur le peuple juif, ainsi que d’autres voix fréquemment marginalisées dans les récits de l’histoire algérienne.
Methodology | Méthodologie
The latent Dirichlet allocation (LDA) algorithm for topic modeling used in this study is unsupervisedOften employed with large corpora that are unreadable because of their size, topic modeling works well for discovery and text summarization tasks. However, this chapter employs it in a novel way to uncover latent biases in a relatively small and perfectly readable corpus. To create each model, I employed the LDA algorithm instantiated in mallet (MAchine Learning for LanguagE Toolkit), a command-line package for topic modeling. A topic coherence algorithm provides guidance on which numbers produce more (computationally) coherent topics. For this project, I used the c_v algorithm in gensim’s library for python, which suggested running models of 11 and 20 topics. Running multiple models at different scales produced remarkably coherent topics that became more detailed at larger scales (those with more topics). It also seemed prudent to try a small number of topics given the limited size and scope of the corpus, so I decided to run a 4-topic model, which proved coherent and provided a good baseline because it delivered a solid representation of the corpus at a general level, which is what one would hope to find with such a small number of topics. The largest model was both coherent and contained granular topics related to minor themes in the corpus.
Once I had generated these various models, I then manually created a nested model that included all of the topics from each scale, finally reducing the scales shown to a hierarchical model with 4-, 7-, 11-, and 20-topics due to the coherence and representative nature of each of these scales. Once I had a model of the corpus, it was time to turn to sentiment analysis to assess any bias present in the materials.
Since we are going to run sentiment analysis on each topic whose complexity has already been reduced to representative terms, an unsupervised, lexicon-based method will suit our purposes well. This also meets our objective to identify an approach that is both accessible for a computational novice and produces fairly reliable results with little initial knowledge of the corpus’ specific contents. For this experiment, I employed the VADER (Valence Aware Dictionary and sEntiment Reasoner) lexicon-based sentiment analysis tool for the programming language Python. This tool is “specifically attuned to sentiments expressed in social media,” so it is trained on terse, short expressions, making it a reasonable tool to try with topic models.[i] The tool also has a pre-built French language model, which made it simple to use for my case study because I did not need to train a new language model. Even though the VADER model is informed by contemporary French texts, the non-transliterated terms (those that are native to French rather than Arabic) have retained their meaning and sense over time from the nineteenth and twentieth centuries through the early twenty-first, so VADER’s algorithm works well for our purposes. When testing VADER against my own close reading of texts, I found that my own subjective human reading of the documents and topics paralleled VADERS’s sentiment analysis scores for both small and large models.
[i] C. J. Hutto and E. E. Gilbert, “VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text,” Python, Eighth International Conference on Weblogs and Social Media (ICWSM-14) (Ann Arbor, MI, 2014), https://github.com/cjhutto/vaderSentiment.

–
Bash, Python, RegEx

–
Mallet LDA Topic Model,
VADER Sentiment Analysis

–
Concordance
(Keyword in context)
L’algorithme d’allocation de Dirichlet latent (LDA) pour la modélisation des sujets utilisé dans cette étude est non supervisé. Souvent utilisée avec de grands corpus illisibles en raison de leur taille, la modélisation des sujets fonctionne bien pour les tâches de découverte et de résumé de texte. Cependant, ce chapitre l’utilise d’une manière nouvelle pour découvrir des biais latents dans un corpus relativement petit et parfaitement lisible. Pour créer chaque modèle, j’ai utilisé l’algorithme LDA instancié dans mallet (MAchine Learning for LanguagE Toolkit), un paquetage en ligne de commande pour la modélisation de sujets. Un algorithme de cohérence des sujets fournit des indications sur les nombres qui produisent des sujets plus cohérents (d’un point de vue informatique). Pour ce projet, j’ai utilisé l’algorithme c_v de la bibliothèque gensim pour python, qui suggère d’exécuter des modèles de 11 et 20 sujets. L’exécution de plusieurs modèles à différentes échelles a produit des sujets remarquablement cohérents qui sont devenus plus détaillés à des échelles plus grandes (celles avec plus de sujets). Il semblait également prudent d’essayer un petit nombre de sujets étant donné la taille et la portée limitées du corpus, j’ai donc décidé d’exécuter un modèle à 4 sujets, qui s’est avéré cohérent et a fourni une bonne base de référence parce qu’il a fourni une représentation solide du corpus à un niveau général, ce qui est ce que l’on espère trouver avec un si petit nombre de sujets. Le modèle le plus large était à la fois cohérent et contenait des sujets granulaires liés à des thèmes mineurs du corpus.
Une fois que j’ai généré ces différents modèles, j’ai ensuite créé manuellement un modèle imbriqué qui incluait tous les sujets de chaque échelle, réduisant finalement les échelles présentées à un modèle hiérarchique avec 4, 7, 11 et 20 sujets en raison de la cohérence et de la nature représentative de chacune de ces échelles. Une fois que j’ai obtenu un modèle du corpus, il était temps de passer à l’analyse des sentiments afin d’évaluer tout biais présent dans les documents.
Étant donné que nous allons effectuer une analyse des sentiments sur chaque sujet dont la complexité a déjà été réduite à des termes représentatifs, une méthode non supervisée, basée sur un lexique, conviendra parfaitement à nos objectifs. Cela répond également à notre objectif d’identifier une approche qui soit à la fois accessible à un novice en informatique et qui produise des résultats relativement fiables avec peu de connaissances initiales sur le contenu spécifique du corpus. Pour cette expérience, j’ai utilisé l’outil d’analyse de sentiments basé sur le lexique VADER (Valence Aware Dictionary and sEntiment Reasoner) pour le langage de programmation Python. Cet outil est ” spécifiquement adapté aux sentiments exprimés dans les médias sociaux “, il est donc entraîné sur des expressions laconiques et courtes, ce qui en fait un outil raisonnable à essayer avec des modèles thématiques[i]. L’outil dispose également d’un modèle de langue française préconstruit, ce qui a facilité son utilisation pour mon étude de cas, car je n’ai pas eu besoin d’entraîner un nouveau modèle de langue. Même si le modèle VADER est basé sur des textes français contemporains, les termes non translittérés (ceux qui sont natifs du français plutôt que de l’arabe) ont conservé leur signification et leur sens au fil du temps, depuis les XIXe et XXe siècles jusqu’au début du XXIe, de sorte que l’algorithme de VADER fonctionne bien pour nos objectifs. Lorsque j’ai testé VADER par rapport à ma propre lecture attentive des textes, j’ai constaté que ma propre lecture humaine subjective des documents et des sujets correspondait aux résultats de l’analyse des sentiments de VADERS pour les modèles de petite et de grande taille.
Results | Résultats
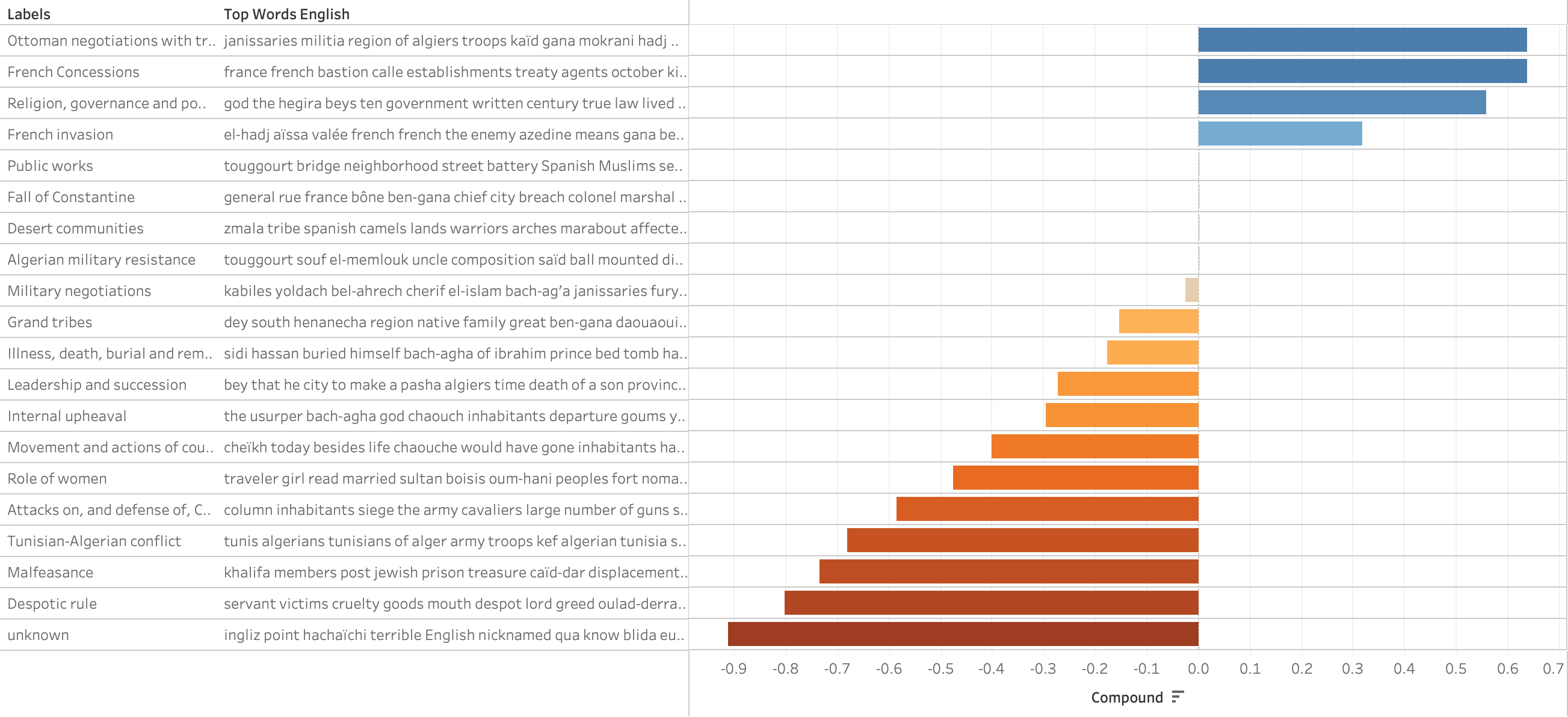
The resulting nested or hierarchical topic model visualizes major and minor themes in the authors’ presentations of Ottoman gubernatorial histories. The most prevalent topics include ‘governance and succession’, ‘Ottoman negotiations with Algerian tribes’, ‘grand tribes’, the ‘Tunisian-Algerian conflict’, and ‘malfeasance’. This last topic deserves more attention as it may indicate a potential, and hitherto unnoticed, authorial bias, as well as historical prejudice operating in Ottoman Algeria.
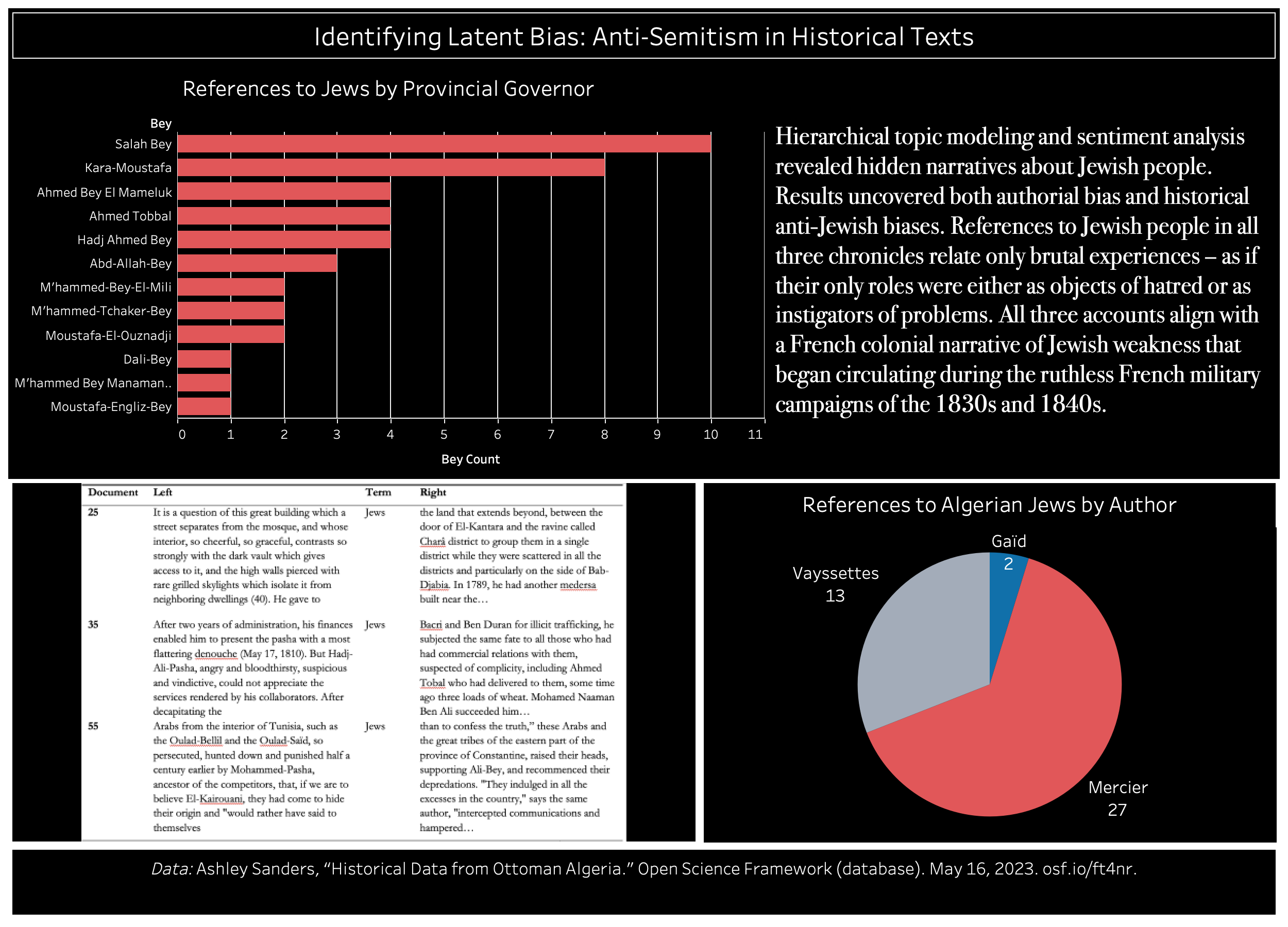
Results indeed uncovered both authorial bias and historical anti-Jewish biases that operated at different moments in Ottoman Algeria, which I corroborated with concordance analysis and close reading. References to Jewish people in all three chronicles solely relate brutal experiences – as if their only roles were either as objects of hatred or as instigators of problems. All three accounts align with a French colonial narrative of Jewish weakness that began circulating during the ruthless French military campaigns of the 1830s and 1840s.
Le modèle thématique emboîté ou hiérarchique qui en résulte permet de visualiser les thèmes majeurs et mineurs dans les présentations des auteurs sur les histoires des gouverneurs ottomans. Les thèmes les plus fréquents sont la “gouvernance et la succession”, les “négociations ottomanes avec les tribus algériennes”, les “grandes tribus”, le “conflit tuniso-algérien” et les “malversations”. Ce dernier sujet mérite plus d’attention car il peut indiquer un biais d’auteur potentiel et jusqu’à présent inaperçu, ainsi que des préjugés historiques opérant dans l’Algérie ottomane.
Les résultats ont en effet mis au jour des préjugés d’auteur et des préjugés historiques anti-juifs qui ont opéré à différents moments dans l’Algérie ottomane, ce que j’ai corroboré par une analyse de concordance et une lecture attentive. Les références au peuple juif dans les trois chroniques relatent uniquement des expériences brutales – comme si leur seul rôle était d’être soit des objets de haine, soit des instigateurs de problèmes. Les trois récits s’alignent sur le récit colonial français de la faiblesse des Juifs qui a commencé à circuler pendant les campagnes militaires françaises impitoyables des années 1830 et 1840.
Further Details
“Detecting Latent Textual Bias with Topic Modeling & Sentiment Analysis,” Presentation at the Digital Humanities 2022 Conference.
Data: Ashley Sanders, “Topic Modeling French-Language Chronicles of Ottoman Constantine, Algeria” (Open Science Framework, May 16, 2023), https://doi.org/10.17605/OSF.IO/WRHAX. This repository contains the corpus, stopwords list, and selected mallet output files for this project.
Jupyter Notebooks: Available in my project GitHub repository at https://github.com/AshleySanders/OttomanAlgeria/tree/master/ConstantineChronicles.
For more details, see my post on this conference presentation on my research site.