
2021 ACH Conference: Consultations & Talk
The Association for Computers and the Humanities (ACH) is a major professional society for the digital humanities. We support and disseminate research and cultivate a vibrant professional community through conferences, publications, and outreach activities. ACH is based in the US, but boasts an international membership (as of November 2015, representing 21 countries worldwide).
Digital Humanities Consultations

- #TextAnalysis
- #DataAnalysis
- #NetworkAnalysis
- #Stats
- Fuzzy project ideas
- #AltAc & career paths
- DH in libraries
- Program building
- #Pedagogy, including #digiped
Talk: Detecting Latent Textual Bias with Topic Modeling and Sentiment Analysis
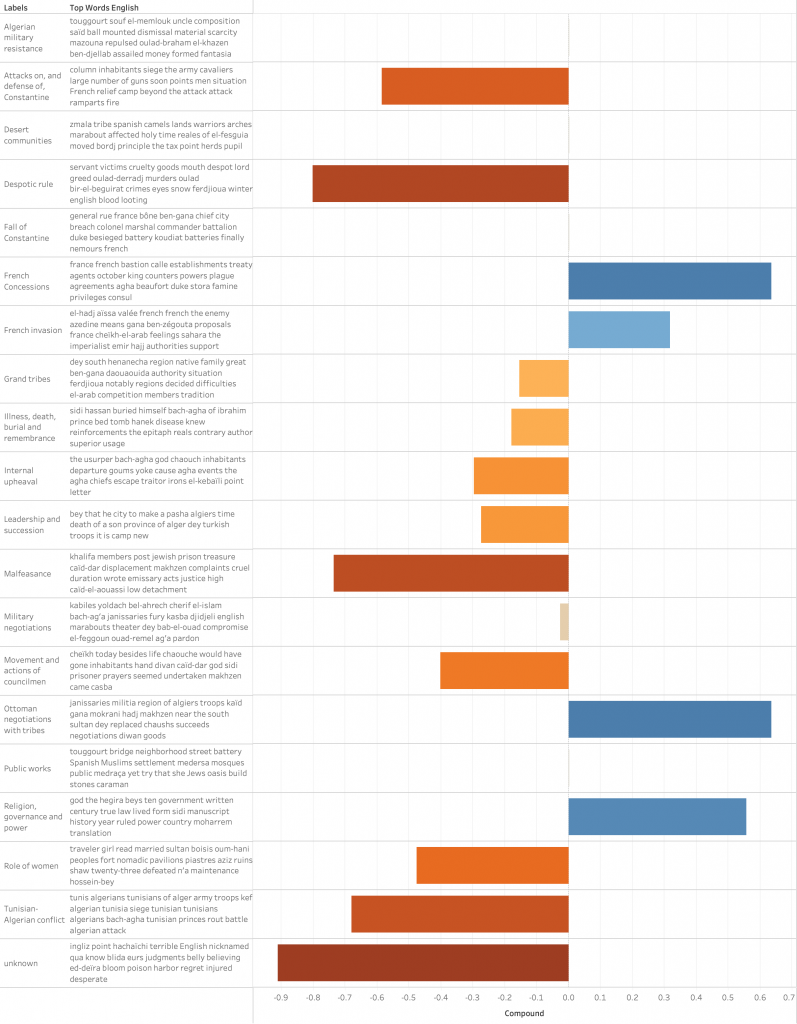
Pairing topic models at different scales with sentiment analysis uncovered the stories of lesser known actors, including women, Jews, Spaniards, and councilmen of provincial governors, as well as the biases inherent in the writing of their histories.
Bias detection is an emerging area of research for digital humanists, computational linguists, and information studies scholars, alike, who point to biases inherent in our algorithms, software, tools, and platforms, but we are only just beginning to examine how computational methods could be used to interrogate our primary textual sources. This project seeks to develop a method for bias detection that can be used at the outset of a historical study with little initial knowledge of the corpus, requires little pre-processing and is both beginner-friendly and language-agnostic. Word2Vec and similarity measures allow us to compare a test corpus against a comparison corpus of biased or neutral terms. This works especially well with contemporary texts, such as online news articles in English, but it becomes an increasingly difficult task with historical or non-English language sources to find appropriate comparative corpora. Building classifiers to identify bias with feature extraction, support vector machine learning algorithms, decision trees, and naïve Bayes approaches work well but require a deep understanding of the corpus and are not accessible to those who are new to computation. Therefore, with the aforementioned aims in mind, I chose to use the latent Dirichlet allocation algorithm for topic modeling to study a set of three chronicles covering the 300 years of Ottoman Algerian history, written in French by two nineteenth-century French scholars and one twentieth-century Algerian scholar.
At just 138 documents and approximately 183,000 words, the corpus is much smaller than one normally uses for topic modeling, but its familiarity made it a promising test case for this approach. Initially, I created topic models of 7-, 9- and 11-topics based on these values’ high coherence scores and then expanded my testing to include models of 4-, 5-, 10-, 15-, and 20-topics. In analyzing these models, it quickly became apparent that the scalar feature of the LDA algorithm was in operation, as the topics of each larger, more detailed model nested under the model with the next most topics, creating a hierarchy. Nesting the models at 4-, 7-, 11-, and 20-topics provided a detailed summary of the corpus, with the 4-topic model serving as a general overview, and the 20-topic model offering a glimpse into the richness of the region’s history with topics related to some of the dominant themes of the corpus, such as “governance and succession,” but also much more granular themes, including “illness, death, burial, and remembrance,” and the “roles of women.” Pairing topic models at different scales (4-, 7-, 11-, and 20-topics) with sentiment analysis of the topic models at 11- and 20-topics, as well as targeted close reading, guided by topics of interest and using the concordance method to identify passages with key terms of interest uncovered the stories of lesser known actors, including women, Jews, Spaniards, and councilmen of provincial governors, as well as the biases inherent in the writing of their histories.
The anti-Arab and/or anti-Turkish sentiments one might expect to observe were absent, but a latent anti-Semitic sentiment appeared in the more granular topic models that, despite my careful reading of the texts, had escaped my notice. The resulting model aids the scholar in weaving the disparate threads of these individuals’ lives into the tapestry of the region’s history, and the method may well be applied to other corpora, topics, languages, and time periods to reveal hidden biases, especially in larger collections of documents that would be impossible for a single scholar to read.